時空大數據支持下的存量規劃方法論
1.3非監督分類與矩陣分解在研究中的使用
分時人口密度數據作為曲線類數據,其自身特點非常適合使用機器學習的方法進行非監督分類。筆者將數據整理為休息日的24小時分時人口數據與工作日的24小時分時人口數據,共48個時刻,結合20種不同類型POI的數量,對3層空間尺度的研究單元進行k-means聚類分析。
為了能夠確定k-means中k的取值,筆者對每組數據均進行了silhouette檢驗,尋找每組合適的k值,保證在分類過程中,既不會出現因為k值過小而忽略某些特征,也不會出現因為k值過大使得多組分類結果高度重合的情況。
為了對時間活動的趨勢規律和地塊人口活動規模進行進一步區分,筆者分別使用了歸一化的48個時刻數據和未歸一化的數據進行非監督學習,使分類結果更加詳細。在進行48個時刻的非監督分類同時,筆者也嘗試了使用非負矩陣分解(NMF)的方法,將每個研究單元48個時刻中的特征提取出來,在放大特征的基礎上進行非監督分類。
2研究結果
2.1地塊尺度研究結果
地塊尺度的分類方法是,采用非負矩陣分解(NMF)的方法先對歸一化后的48個變量進行降維(降成5維),然后采用k-means聚類的方法對降維之后的5個變量進行聚類。多次進行silhouette檢驗,發現k=9時,分類精度最高。
從地塊尺度分類結果圖可以看出,該方法對商務辦公、商業商務混合、商業識別度最高,對游憩—公園、居住主導、商住混合—居住為主等功能的地塊也有較好的識別度,而混合—居住主導及其他兩類混合類則無法準確判斷,實際上這3類在五環內的地塊中所占比例非常小,可以說,總體上基于地塊尺度的地塊分類方法具有較高的精度。
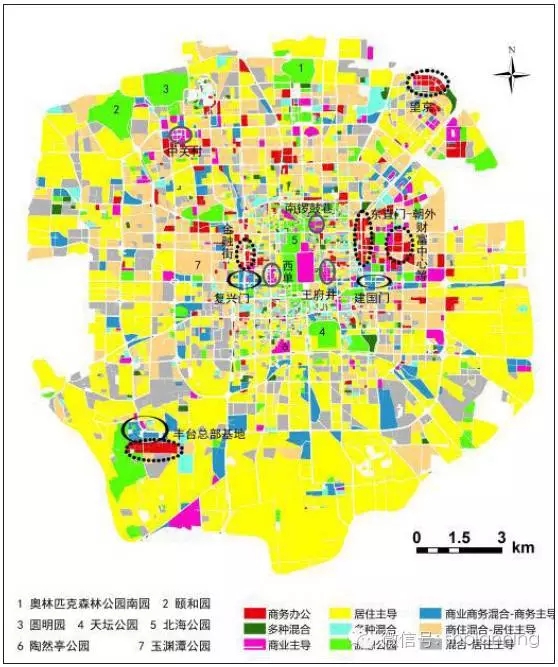
地塊尺度分類結果
除對典型的功能區有較高的識別度之外,該分類對非典型功能區中精細地塊也能有較好的識別。以奧林匹克森林公園所在區域為例,這塊區域包括了居住、商業、辦公、游憩公園等多種類型。
地塊1經過機器學習識別出的結果是游憩公園類型,所表現的曲線特征為周末人多、平時人少、高峰在下午14—17點,與人們游憩娛樂的行為習慣一致,進一步對比百度地圖的結果,發現該地塊為奧林匹克森林公園南園所在地,為綠地類型用地。
地塊2經過機器學習識別出的結果是商務主導用地,曲線特征為明顯的周末幾乎無人、平時人多、10—18點長高峰的特征,與人們工作的行為習慣一致,而在百度地圖中顯示該地塊為京東總部未搬遷之前的辦公所在地,為商務辦公用地類型。
地塊3識別的結果是商業主導的用地類型,曲線表現為周末、平時略突出的雙高峰特征,由于該購物中心為片區級購物中心,主要服務周邊居住、辦公的人群,因此商業特征相較商業中心不太明顯,但仍表現為商業主導的特征,而百度地圖上顯示該地塊為漂亮陽光廣場,為商業服務業用地類型。曲線以及地圖實景均驗證了本部分所用分類方法在精細地塊尺度上具有較高的識別度。
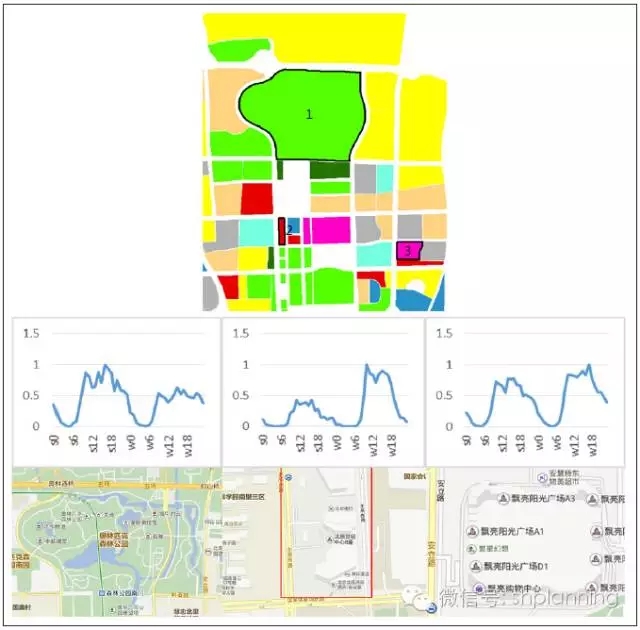
奧林匹克森林公園區域地塊識別功能、對應曲線、實際功能
編輯:lianqi

